原题链接:力扣热题-HOT100
我把刷题的顺序调整了一下,所以可以根据题号进行参考,题号和力扣上时对应的,那么接下来就开始刷题之旅吧~
1-8题见LeetCode-hot100题解—Day1
9-16题见LeetCode-hot100题解—Day2
17-24题见LeetCode-hot100题解—Day3
25-34题见LeetCode-hot100题解—Day4
注:需要补充的是,如果对于每题的思路不是很理解,可以点击链接查看视频讲解,是我在B站发现的一个宝藏UP主,视频讲解很清晰(UP主用的是C++),可以结合视频参考本文的java代码。
力扣hot100题解 32-40
- 39.组合总和
- 46.全排列
- 48.旋转图像
- 49.字母异位词分组
- 50.Pow(x,n)
- 53.最大子数组和
- 55.跳跃游戏
- 56.合并区间
39.组合总和
思路:
本题是典型的深度优先搜索,需要注意的一点是,每个数字是可以重复选择的,所以在深度优先搜索的时候索引值idx不用改变,具体的思路可以参考视频讲解-组合总和。
时间复杂度:
时间复杂度分析:
- 在最坏情况下,
DFS会遍历所有可能的组合。 - 对于每个数字,都有两种选择:选择或者不选择。
因此,时间复杂度为O(2^N),其中N是候选数字的数量。
代码实现:
class Solution {
public List<List<Integer>> combinationSum(int[] candidates, int target) {
List<List<Integer>> ans = new ArrayList<>();
List<Integer> com = new ArrayList<>();
dfs(candidates,target,0,ans,com);
return ans;
}
private void dfs(int[] candidates,int target,int idx,List<List<Integer>> ans, List<Integer> com){
if(target == 0){
ans.add(new ArrayList<>(com));
return ;
}
if(idx == candidates.length) return ;
dfs(candidates,target,idx + 1,ans,com);
if(target >= candidates[idx]){
com.add(candidates[idx]);
dfs(candidates,target - candidates[idx],idx,ans,com);
com.remove(com.size() - 1);
}
}
}
46.全排列
思路:
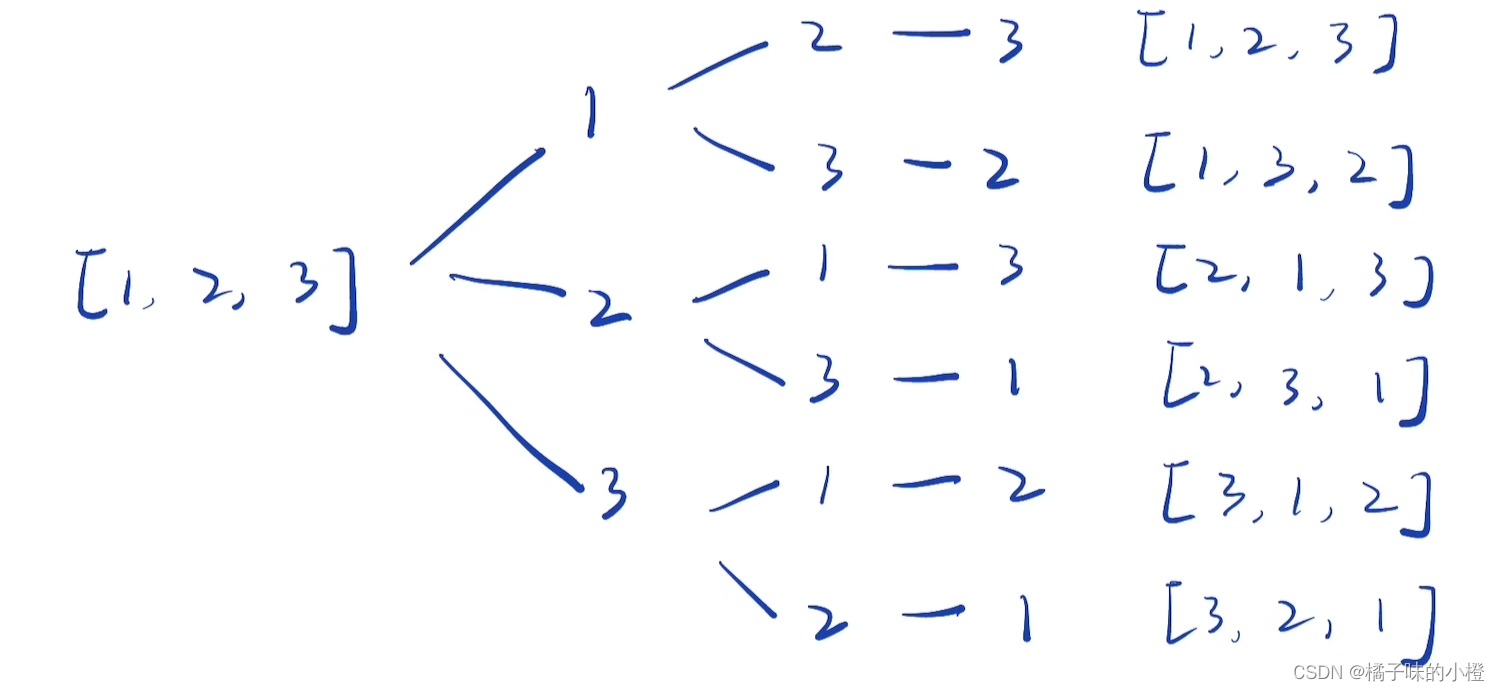
本题是一个典型的dfs问题,和39题很相似,以[1,2,3]为例模拟dfs的过程如下,需要注意的是选择数字进行组合的依据是对应的数字在之前没有被使用,所以需要一个used布尔数组来记录数组元素的使用情况,视频讲解点击视频讲解-全排列。
时间复杂度:
在每个位置上,都有n种选择,因此总共有 n! 种排列,故时间复杂度为O(n^n)。
代码实现:
class Solution {
List<List<Integer>> ans = new ArrayList<>();
List<Integer> combine = new ArrayList<>();
public List<List<Integer>> permute(int[] nums) {
boolean[] used = new boolean[nums.length];
dfs(nums,0,used);
return ans;
}
private void dfs(int[] nums,int idx,boolean[] used){
if(idx == nums.length){
ans.add(new ArrayList<>(combine));
return ;
}
for(int i = 0;i < nums.length;i++){
if(!used[i]){
combine.add(nums[i]);
used[i] = true;
dfs(nums,idx+1,used);
used[i] = false;
combine.remove(combine.size() - 1);
}
}
}
}
48.旋转图像
思路:
对二维数组进行顺时针90°的旋转,可以拆分成先将数组按照主对角线进行翻转,然后再将得到的数组左右翻转,模拟的过程如图所示,所以只需要对数组进行两次循环先进行主对角线翻转,然后进行左右翻转即可,详细的讲解点击视频讲解-旋转图像。

时间复杂度:
用到了两层for循环,故时间复杂度为O(n^2)。
代码实现:
class Solution {
public void rotate(int[][] matrix) {
int n = matrix.length;
//按主对角线翻转
for(int i = 0; i < n; i++){
for(int j = 0; j < i; j++){
int temp = matrix[i][j];
matrix[i][j] = matrix[j][i];
matrix[j][i] = temp;
}
}
//左右翻转
for(int i = 0; i < n; i++){
for(int j = 0; j < n / 2; j++){
int temp = matrix[i][j];
matrix[i][j] = matrix[i][n - j - 1];
matrix[i][n - j - 1] = temp;
}
}
}
}
49.字母异位词分组
思路:
本题需要将字母异位词分组,然后返回,可以发现字母异位词的在按照字母序排序后结果都是一样的,例如[abc,bca,cba]按照字母序排序后得到的结果都是abc,所以我们可以使用哈希表以字母序的字符串为key,将所有重新排列的单词作为value,在处理结束整个字符串数组后输出map的所有value值即可。详细的视频点击视频讲解-字母异位词分组。
时间复杂度:
这段代码的时间复杂度为O(NKlogK),其中N表示字符串数组的长度,K表示字符串的最大长度。
代码中的循环遍历了字符串数组,所以它的时间复杂度是O(N)。
在每次循环中,将字符串转换为字符数组需要O(K)的时间复杂度。然后对字符数组进行排序需要O(KlogK)的时间复杂度。因此,每次循环的总时间复杂度是O(KlogK)。
最后,将排序后的字符串作为键值,将原始字符串添加到对应的列表中,这个操作的时间复杂度是O(1)。
因此,整个代码的时间复杂度为O(NKlogK)。
代码实现:
class Solution {
public List<List<String>> groupAnagrams(String[] strs) {
Map<String,List<String>> record = new HashMap<>();
for(String str : strs){
char[] chars = str.toCharArray();
Arrays.sort(chars);`在这里插入代码片`
String key = new String(chars);
if(!record.containsKey(key)){
record.put(key,new ArrayList<>());
}
record.get(key).add(str);
}
return new ArrayList<>(record.values());
}
}
知识点总结:
关于java中的哈希表的用法
Map在解决一些算法问题时经常会用到,所以在这里对Map的API总结一下,方便后续刷题的时候来查看使用,参考博客java map使用(这个博客里面包含了其他哈希结构的API,很赞,推荐去看,这里我只是摘抄出来Map的常用API)。
void clear() :删除Map中的所有键值对
boolean containsKey(key) :查询Map中是否包含指定的key,如果包含则返回true
boolean containsValue(value) :查询Map中是否包含指定的value,如果包含则返回true
Set entrySet() :返回Map中所包含的键值对所组成的Set集合 ,每个集合元素都是Map.Entry的对象,Entry是Map的内部类
Object get(key):返回key对应的value,如果没有key则返回null
boolean isEmpty():查询Map是否为空,为空返回true
Set keySet():返回该Map中所有key所组成的set集合
Object put(key,value):添加一个键值对,如果已有一个相同的key值则新的键值对覆盖旧的键值对
void putAll(Map m):将指定Map中的键值对复制到Map中
Object remove(key) :删除指定key所对应的键值对,返回key所关联的value,如果key不存在则返回null
int size():返回该Map里的键值对的个数
Collection values():返回该Map中所有value组成的Collection
Map中包含一个内部类:Entry,该类封装了一个键值对,它包含了三个方法:
Object getKey():返回该Entry里包含的key值
Object getValue():返回该Entry里包含的value值
Object setValue(value) :设置该Entry中包含的value值,并返回新设置的value值。
50.Pow(x,n)
思路:
本题暴力的解法是直接循环累成x,但是这样做时间复杂度会很高,导致超时,这里我们用快速幂来解决,快速幂在算法题中也较为常见,其思想是我们将n转换成二进制,可以使得我们累乘的次数变少,如下图的过程所示。第一步我们需要先得到x的各二次幂的值,然后根据n的二进制来决定需要将哪些二次幂累乘(如果没有理解的请看下图),如果不是很明白可以点击观看视频讲解视频讲解-Pow(x,n)。

时间复杂度:
该代码的时间复杂度为O(logN)。循环的次数取决于n的二进制表示中1的个数,而n的二进制表示最多有logN位。所以,循环的次数最多为logN次,因此时间复杂度为O(logN)。
代码实现:
class Solution {
public double myPow(double x, int n) {
//防止溢出重新定义为long long类型
long N = n;
//如果n是负数,先处理成整数,在最后得到结果后处理成1/ans即可
if(n < 0) N = -N;
double ans = 1.0;
while(N > 0){
if( (N & 1) == 1) ans *= x;
x *= x;
N >>= 1;
}
return n < 0 ? 1 / ans :ans;
}
}
53.最大子数组和
思路:
本题采用动态规划来求解,动态规划最重要的是得到动态规划方程,在本题中我们要得到数组中和最大的连续子数组,用f(i)来表示到下标为i时子数组的和,那么f(i-1)就是指到下标为i-1的子数组的和,如果f(i-1)<0,所以要得到最大的和,f(i)就是nums[i],如果f(i-1)>0,那么f(i)的最大和为f(i-1)+nums[i],需要注意的题目中要求是连续的子数组,如果不是连续子数组,那么就不能用该方法求解,可以使用dfs。如果没有理解上面的讲解可以点击观看视频讲解视频讲解-最大子数组和。
时间复杂度:
由于只对数组进行了一次遍历,所以时间复杂度为O(n)。
代码实现:
class Solution {
public int maxSubArray(int[] nums) {
int pre = nums[0];
int ans = nums[0];
for(int i = 1; i < nums.length;i++){
pre = pre > 0 ? pre + nums[i] : nums[i];
ans = Math.max(ans,pre);
}
return ans;
}
}
55.跳跃游戏
思路:
通过题意可以得出,当数组的下标大于此下标之前所有下标可以跳转的最大位置,则说明无法到达最后一个下标,因为这时该下标是无法到达的,所以也无法到达最后一个图标。如果没有理解的话,可以点击观看视频讲解视频讲解-跳跃游戏,里面有具体的过程模拟。
时间复杂度:
由于只对数组进行了一次遍历,所以时间复杂度为O(n)。
代码实现:
class Solution {
public boolean canJump(int[] nums) {
int maxPos = 0;
for(int i = 0; i < nums.length;i++){
if(i > maxPos) return false;
maxPos = Math.max(maxPos,i + nums[i]);
}
return true;
}
}
56.合并区间
思路:
本题使用扫描线法来解决,首先要对二维数组进行排序,根据其中数组元素的第一个数字进行升序排列(这里代码里用了一种正则表达式的排序方法,会在知识点总结进行介绍),在排序完成之后进行扫描,有三种情况,我们将最前面的数组区间设置为[start,end],向后扫描:
-
后面的区间的
starti大于end,那么直接将前一个区间加入结果集中 -
后面的区间的
starti小于end,这里又会分出两种情况:(1)后面的区间完全包含在前面的区间
(2)后面的区间的endi大于前面区间的end
以上两种情况我们都需要将end更新为最大的end值,所以可以归结为一类
如果还是不太理解的话可以点击视频讲解-合并区间。
时间复杂度:
首先将区间按照起始时间排序,这需要O(nlogn)的时间复杂度,然后遍历排序后的区间,维护一个当前区间的起始时间和结束时间。如果遇到与当前区间重叠的新区间,就更新当前区间的结束时间。如果遇到与当前区间不重叠的新区间,就把当前区间加入到结果列表中,然后更新当前区间的起始时间和结束时间,这个遍历过程需要O(n)的时间复杂度。所以总的时间复杂度是O(nlogn) + O(n) = O(nlogn)。
代码实现:
class Solution {
public int[][] merge(int[][] intervals) {
//将ntervals按照数组元素的第一个数排序
Arrays.sort(intervals,(a,b) -> a[0] - b[0]);
List<int[]> ans = new ArrayList<>();
int start = intervals[0][0];
int end = intervals[0][1];
for(int[] interval : intervals){
if(interval[0] > end){
ans.add(new int[]{start,end});
start = interval[0];
end = interval[1];
}else{
end = Math.max(end,interval[1]);
}
}
ans.add(new int[]{start,end});
return ans.toArray(new int[ans.size()][]);
}
}
知识总结:
1.List的常见使用
//向List中添加元素
List.add(e)
//根据索引获取元素
List.get(index)
//按照索引删除
List.remove(index)
//按照元素内容删除
List.remove(Object o)
//判断List中是否包含某个元素,返回true或false
List.contains(Object o)
//使用element替换该索引处的值
List.set(index,element)
//在该索引位置插入一个值
List.add(index,element)
//返回该值的第一个索引
List.indexOf(Object o)
//返回该值的最后一个索引
List.lastIndexOf(Object o)
//截取List的部分元素,
//注意这里时左闭右开,即fromIndex的值要包括,但是toIndex的值不包括,索引从0开始
List.subList(fromIndex, toIndex)
//返回该List中的元素数
List.size()
//对比两个List的所有元素是否相同
//两个相等对象的equals方法一定为true, 但两个hashcode相等的对象不一定是相等的对象
List1.equals(List2)
//判断List是否为空
List.isEmpty()
//返回Iterator集合对象
List.iterator()
//将List转换为字符串
List.toString()
//将List转换为数组
List.toArray()
2.二维数组的排序
Arrays.sort(intervals,(a,b) -> a[0] - b[0]);
intervals是一个二维数组,每个元素都是一个包含两个整数的数组,表示一个时间区间的开始和结束时间。(a, b) -> a[0] - b[0]是一个lambda表达式,用作排序的比较函数。它比较两个数组a和b的第一个元素,如果a[0]小于b[0],则返回一个负数,表示a应该排在b前面。经过排序,intervals数组中的时间区间会按照开始时间的升序排列。
为什么不能直接使用Arrays.sort(intervals)呢?
由于 intervals 数组中的元素是 int[] 类型的数组。在这种情况下,直接使用 Arrays.sort(intervals) 是不正确的,因为 Java 默认使用数组元素的比较顺序进行排序,对于 int[] 类型来说,比较的是数组的引用,而不是数组中的元素。
对于一维数组,比如 int[] 类型,Arrays.sort() 方法可以直接使用,它会按照数组元素的自然顺序进行排序。
但是对于二维数组 int[][] 类型,情况就不太一样了。因为二维数组的元素是一维数组,所以 Arrays.sort() 默认是按照一维数组的引用进行排序的,而不是按照一维数组中的元素进行排序。
为了按照二维数组中的特定元素进行排序,需要提供一个自定义的比较器,例如 (a, b) -> a[0] - b[0] ,这样可以告诉 Arrays.sort() 方法按照二维数组中的第一个元素进行排序。
待续…